UTF-8 정리
UTF8의 개념과 인코딩/디코딩 방식 정리. BOM과�까지

Intro
이 세상에 존재하는 모든 인코딩을 다 합쳐도, UTF-8의 사용빈도보다 낮다는 걸 아시나요?
UTF-8은 개발자가 아니어도 한 번쯤 들어봤을 만큼 익숙한 용어에요.
저도 예전엔 “한글이 깨지면 인코딩 바꾸면 되지!” 정도로만 생각했죠.
이 글에서는 UTF-8이 문자를 어떻게 0과 1로 인코딩하는지,
그리고 컴퓨터가 그 0과 1을 어떻게 다시 디코딩해서 문자열로 해석하는지 알아볼게요.
UTF-8이란?
UTF-8은 Unicode Transformation Format - 8bit의 줄임말이에요. 말 그대로, 유니코드를 1바이트 단위로 인코딩하는 방식이죠.
유니코드란?
유니코드는, “모든 문자를 컴퓨터에서 표현할 수 있도록 설계된 산업 표준”이에요.
각 문자에는 U+0000부터 U+10FFFF까지의 고유한 코드포인트가 부여되는데, 최대 1,114,112개(= 0x10FFFF + 1)의 문자를 표현할 수 있어요.
유니코드는 지금도 계속 확장되고 있고, 현재(2025-07 기준, v16.0.0) 총 154,998자가 정의돼 있어요.
UTF-8은 유니코드를 1바이트 단위로 쪼개서 인코딩하되, 문자마다 1~4바이트까지 사용하는 ‘가변 길이 유니코드 인코딩’ 방식이에요.
가변길이란?
말 그대로, 문자마다 서로 다른 길이를 가진다는 뜻인데, 자주 쓰이는 문자는 짧게, 잘 쓰이지 않는 문자는 길게 저장하는 방식이에요.
| 문자 | 코드포인트 | 바이트 |
|---|---|---|
| A | U+0041 | 1바이트 |
| × | U+00D7 | 2바이트 |
| 가 | U+AC00 | 3바이트 |
| 👍 | U+1F44D | 4바이트 |
효율적으로 문자열을 저장하는 건 좋지만, 결국 우리가 다루는 문자열은 메모리 속에서 01010100... 의 바이트 배열일 뿐이죠. 이 바이트 배열에서 어떻게 문자를 구분할 수 있을까요?
디코딩과 인코딩
UTF-8 디코딩
여기서 말하는 디코딩은, 바이트 배열을 코드포인트로 변환하는 걸 뜻해요
UTF-8은 다음과 같은 디코딩 규칙을 가지고 있어요:
- 첫 바이트의 앞쪽에서 연속된 1의 개수로, 총 길이를 결정해요.
0xxxxxxx→ 1바이트110xxxxx→ 2바이트1110xxxx→ 3바이트11110xxx→ 4바이트- 0이 처음 등장한 뒤의 비트들은 문자의 정보를 담고 있어요.
- 두 번째 바이트부터는 모두
10xxxxxx형태로 시작해요.- 여기서 앞의 2비트를 제외한 6비트
xxxxxx는 문자의 정보를 담고 있어요.
- 여기서 앞의 2비트를 제외한 6비트
문자 정보를 가지고 있는 비트들을 모두 이으면, 원래의 유니코드 코드포인트가 나와요.
그림으로 보면 다음과 같아요:
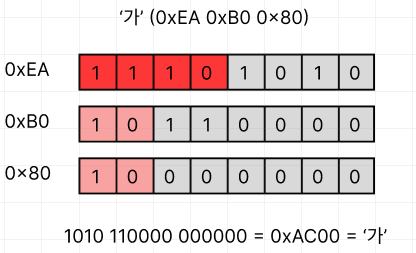
- 첫 번째 바이트가
1110xxxx이니깐, 이 문자는 3바이트짜리에요. - 각 바이트에서 문자열 정보를 나타내는 비트를 모두 이으면
0b1010110000000000이 되고, 16진수로는0xAC00, 즉U+AC00('가') 가 되는 거에요.
UTF-8 인코딩
여기서 말하는 인코딩은, 유니코드 코드포인트를 바이트 배열로 변환하는 걸 뜻해요.
인코딩 로직은 다음과 같아요:
- 해당 코드포인트가 몇 바이트로 인코딩될지 결정해요.
- U+0000 ~ U+007F → 1바이트
- U+0080 ~ U+07FF → 2바이트
- U+0800 ~ U+FFFF → 3바이트
- U+10000 ~ U+10FFFF → 4바이트
- 코드 포인트를 비트로 바꾸고, 각 바이트의 빈 자리
x에 채워 넣어요.0xxxxxxx→ 1바이트110xxxxx 10xxxxxx→ 2바이트1110xxxx 10xxxxxx 10xxxxxx→ 3바이트11110xxx 10xxxxxx 10xxxxxx 10xxxxxx→ 4바이트
실제 코드로 살펴보면 다음과 같아요:
const TAG_CONT: u8 = 0b1000_0000; // 이어지는 바이트의 접두 비트: 10xxxxxx
const TAG_TWO_B: u8 = 0b1100_0000; // 2바이트 문자용 leading byte : 110xxxxx
const TAG_THREE_B: u8 = 0b1110_0000; // 3바이트 문자용 leading byte : 1110xxxx
const TAG_FOUR_B: u8 = 0b1111_0000; // 4바이트 문자용 leading byte : 11110xxx
const MAX_ONE_B: u32 = 0x80; //128- 1바이트 인코딩의 최대 코드 포인트 (U+007F + 1)
const MAX_TWO_B: u32 = 0x800; //2048- 2바이트 인코딩의 최대 코드 포인트 (U+07FF + 1)
const MAX_THREE_B: u32 = 0x10000; //65536- 3바이트 인코딩의 최대 코드 포인트 (U+FFFF + 1)
/// 코드 포인트를 인코딩할 때 필요한 바이트 수
fn len_utf8(code: u32) -> usize {
match code {
..MAX_ONE_B => 1,
..MAX_TWO_B => 2,
..MAX_THREE_B => 3,
_ => 4,
}
}
/// 실제로 변환하는 함수
pub const fn encode_utf8_raw(code: u32, dst: &mut [u8]) -> &mut [u8] {
let len = len_utf8(code); // 1. 몇바이트로 인코딩될지 결정
match (len, &mut *dst) { // 2. 비트마스크를 통해 각 바이트마다 채워넣음
(1, [a, ..]) => {
*a = code as u8;
}
(2, [a, b, ..]) => {
*a = (code >> 6 & 0x1F) as u8 | TAG_TWO_B;
*b = (code & 0x3F) as u8 | TAG_CONT;
}
(3, [a, b, c, ..]) => {
*a = (code >> 12 & 0x0F) as u8 | TAG_THREE_B;
*b = (code >> 6 & 0x3F) as u8 | TAG_CONT;
*c = (code & 0x3F) as u8 | TAG_CONT;
}
(4, [a, b, c, d, ..]) => {
*a = (code >> 18 & 0x07) as u8 | TAG_FOUR_B;
*b = (code >> 12 & 0x3F) as u8 | TAG_CONT;
*c = (code >> 6 & 0x3F) as u8 | TAG_CONT;
*d = (code & 0x3F) as u8 | TAG_CONT;
}
...
}
실제 rust std의 코드에요
이 함수에 ‘가’ 가 들어갔을 때를 가정해볼게요.
- ‘가’는 U+AC00이므로, 10진수로는
44032,비트로는0b00000000_00000000_10101100_00000000이에요. - 이 값은
MAX_THREE_B이하이므로, UTF-8에서 3바이트로 인코딩돼요. - 이제
10101100_00000000— 즉, 총 16비트를UTF-8 규칙에 따라 아래 3개의 바이트 구조에 나눠 담아야 해요:- 첫 번째 바이트:
1110xxxx(상위 4비트) - 두 번째 바이트:
10xxxxxx(중간 6비트) - 세 번째 바이트:
10xxxxxx(하위 6비트)
- 첫 번째 바이트:
- 먼저 첫 바이트의 빈 자리(
xxxx)에 상위 4비트인0b1010를 넣으면:11101010→0xEA - 두 번째 바이트는 중간 6비트인
0b110000을 넣어야 하니:10+110000→10110000→0xB0 - 마지막으로 세 번째 바이트에는 하위 6비트인
0b000000을 넣어요:10+000000→10000000→0x80
이렇게 ‘가’라는 문자열이 [0xEA,0xB0,0x80] 로 인코딩되요.
UTF-8이 깨졌��?
지금까지 봤듯이, UTF-8에는 명확한 규칙이 있어요. 하지만 이 규칙을 지키지 않은 잘못된 바이트들이 입력된다면 어떻게 될까요?
이때 우리가 흔히 �로 알고 있는 U+FFFD(Replacement Character)가 등장해요. 디코더는 유효하지 않은 바이트 시퀀스를 만나면 해당 부분을 �로 대체하고, 뒤의 문자들을 이어 디코딩하려고 해요. (물론, 문자열이 한 번 깨졌다면 그 이후도 온전하지 않을 가능성은 높아요.)
...
const REPLACEMENT: &str = "\\u{FFFD}";
for chunk in iter {
res.push_str(chunk.valid());
if !chunk.invalid().is_empty() {
res.push_str(REPLACEMENT);
}
}
...UTF-8 BOM
BOM은 Byte Order Mark의 줄임말로, 유니코드 텍스트 파일에 추가되는 특별한 문자 U+FEFF 를 말해요.
이는 원래 UTF-16, UTF-32와 같은 인코딩에서 바이트 안 비트 표시 순서(Endian)를 나타내기 위해 사용됐지만, UTF-8은 바이트 단위로 읽으면 되기 때문에 사실상 필요 없어요.
그럼에도 불구하고, UTF-8 파일에 BOM이 붙는 경우가 있는데, 이는 윈도우같은 환경에서 UTF-8 인코딩을 명확히 알려주려는 목적이죠.
BOM은 UTF-8에서 필수가 아니고, 최근 Windows도 BOM 없이 잘 작동하니깐, 특별한 이유가 없다면 BOM을 붙이지 않는 걸 권장해요.(리눅스나 웹 환경에서는 오히려 문제를 일으킬 수 있어요)
Final
사실 가볍게 정리할 생각이었는데, 막상 파고들다 보니 생각보다 시간이 많이 들었어요. 사실 제가 직접 UTF-8 변환을 코드를 쓸 일은 거의 없겠지만, 나중에 누가 물어봤을 때 기본 개념 정도는 설명해 줄 수 있을 것 같아요.
3-Point
- UTF-8은 문자를 1~4바이트로 저장하는 가변 길이 인코딩 방식이에요.
- 첫 바이트에서 연속된 1의 개수를 통해 인코딩된 문자열이 몇 바이트인지 알 수 있고, 정보 비트를 조합해 원래의 유니코드 코드포인트를 알 수 있어요.
- 우리가 컴퓨터를 사용할 때 당연하게 생각하는 것들은 사실 당연하지 않아요. 앞선 누군가가 치밀하게 설계한 내부 로직 위에 있기 때문에 당연해 보이는 거에요.



