Cuckoo filter 원리
Cuckoo filter 동작 원리에 대해 알아보자. (feat. redis)

Intro
Cuckoo Filter(CF)는 Bloom Filter처럼 메모리 효율적으로 집합에 원소가 있는지 확률적으로 확인하는 자료구조에요.
BF보다 좀 더 많은 메모리를 필요로 하지만, 대신 원소를 삭제할 수 있어요!
이름에 뻐꾸기(cuckoo)가 들어간 데엔 꽤 흥미로운 이유도 있어요.
이제부터 CF의 개념과 동작 원리에 대해 살펴볼게요.
Cuckoo hashing
뻐꾸기는 남의 둥지에 몰래 알을 낳고, 부화한 후 관심을 독차지하기 위해 원래 있던 알들을 둥지 밖으로 밀어버리는 습성을 가지고 있어요. 쓰레기
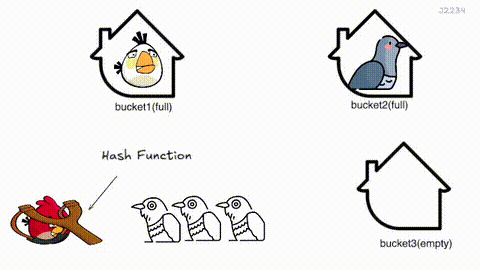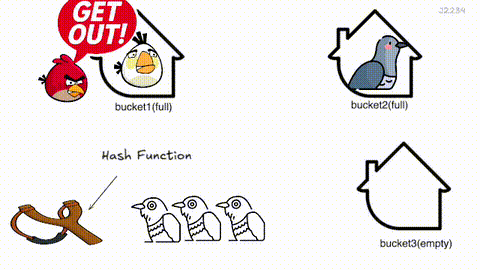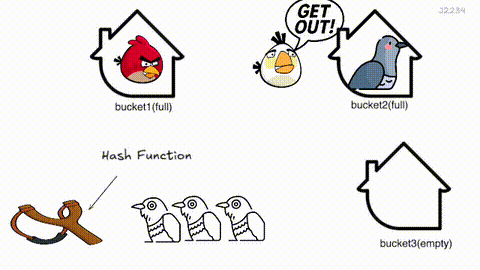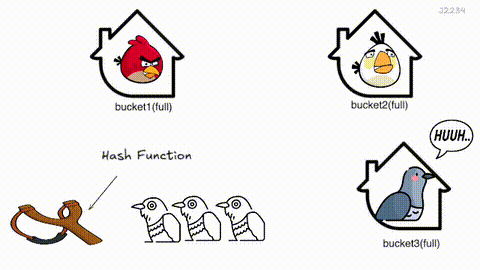
Cuckoo Hashing 은 해시 충돌을 뻐꾸기처럼 해결하는 기법이에요.
원소가 삽입될 때 버킷 후보 위치(해시값) 2개를 구해, 비어 있는 자리에 삽입해요. 만약 두 자리 모두 찼다면, 자기가 들어가고 기존에 있던 항목을 쫓아내죠. 쫓겨난 원소도 또 하나의 다른 후보 위치가 있겠죠? 그 자리가 차있으면 또 쫓아내고… 이 과정을 빈자리가 생길 때까지 반복해요.
Cuckoo Filter
CF는 앞서 본 Cuckoo hashing 아이디어를 사용하지만, 원소 전체가 아닌 원소의 지문만 저장해요.
덕분에 메모리를 아끼면서도 삭제가 가능하죠.
대표적인 연산인 insert, find, delete 의 작동 원리를 살펴볼게요.
LookupParams
Cuckoo Filter의 대표적인 연산은 모두 두 개의 후보 위치와 지문(fp)을 사용하는데, 이 때 필요한 정보를 LookupParams 구조체가 가지고 있어요. getLookupParams() 함수가 다음과 해시값으로 빈 구조체를 채워주죠:
hash % 255 + 1로 fp 계산- hash 를 그대로 h1 로 사용
- h1 과 fp 를 조합해서 h2 생성
typedef struct {
CuckooHash h1; //uint64_t 해시값1
CuckooHash h2; //uint64_t 해시값2
CuckooFingerprint fp; //uint8_t 지문
} LookupParams;
static CuckooHash getAltHash(CuckooFingerprint fp, CuckooHash index) {
return ((CuckooHash)(index ^ ((CuckooHash)fp * 0x5bd1e995)));
}
static void getLookupParams(CuckooHash hash, LookupParams *params) {
params->fp = hash % 255 + 1; //지문
params->h1 = hash; //후보1
params->h2 = getAltHash(params->fp, params->h1); //후보2
}
Insert
원소를 삽입할 땐 이렇게 동작해요:
LookupParams로 후보 위치(버킷) 2개와 fp 계산- 후보 버킷에 자리가 있다면 거기 삽입하고 끝
- 없으면 cuckoo hashing으로 밀어내기 시작
- 아무리 밀어내도 안끝나면 삽입 실패
밀어내는 과정만 살짝 보면, 최대 반복 횟수 안에서 성공할 때까지 쫓아내고 있어요:
...
CuckooFingerprint fp = params->fp; //uint8_t 지문
uint16_t counter = 0;
uint32_t victimIx = 0;
uint32_t ii = params->h1 % numBuckets;
while (counter++ < maxIterations) {
uint8_t *bucket = &curFilter->data[ii * bucketSize];
swapFPs(bucket + victimIx, &fp);
ii = getAltHash(fp, ii) % numBuckets; // 후보 버킷
// Insert the new item in potentially the same bucket
uint8_t *empty = Bucket_FindAvailable(&curFilter->data[ii * bucketSize], bucketSize);
if (empty) {
*empty = fp;
return CuckooInsert_Inserted;
}
victimIx = (victimIx + 1) % bucketSize;
}
...
//실제로 subfilter 추가해서 다시 시도하고
//필터추가 실패하면 삽입 실패
Find
원소를 찾을 땐 이렇게 동작해요:
LookupParams로 후보 위치(버킷) 2개와 fp 계산- 두 후보 버킷 중 어디든 슬롯에 fp가 있으면 true, 없으면 false
static int Filter_Find(const SubCF *filter, const LookupParams *params) {
uint8_t bucketSize = filter->bucketSize;
uint64_t loc1 = SubCF_GetIndex(filter, params->h1);
uint64_t loc2 = SubCF_GetIndex(filter, params->h2);
return Bucket_Find(&filter->data[loc1], bucketSize, params->fp) != NULL ||
Bucket_Find(&filter->data[loc2], bucketSize, params->fp) != NULL;
}
static uint8_t *Bucket_Find(CuckooBucket bucket, uint16_t bucketSize, CuckooFingerprint fp) {
for (uint16_t ii = 0; ii < bucketSize; ++ii) {
if (bucket[ii] == fp) {
return bucket + ii;
}
}
return NULL;
}
Delete
원소를 삭제하는 건 find와 거의 비슷해요:
LookupParams로 후보 위치(버킷) 2개와 fp 계산- 두 후보 버킷 어디든 슬롯에 fp가 있으면 지우고 true 아니면 false
static int Filter_Delete(const SubCF *filter, const LookupParams *params) {
uint8_t bucketSize = filter->bucketSize;
uint64_t loc1 = SubCF_GetIndex(filter, params->h1);
uint64_t loc2 = SubCF_GetIndex(filter, params->h2);
return Bucket_Delete(&filter->data[loc1], bucketSize, params->fp) ||
Bucket_Delete(&filter->data[loc2], bucketSize, params->fp);
}
static int Bucket_Delete(CuckooBucket bucket, uint16_t bucketSize, CuckooFingerprint fp) {
for (uint16_t ii = 0; ii < bucketSize; ii++) {
if (bucket[ii] == fp) {
bucket[ii] = CUCKOO_NULLFP; //0임
return 1;
}
}
return 0;
}
중복 삽입과 CF.ADD vs CF.ADDNX
기본적으로 cuckoo filter에 원소를 삽입하면 CuckooFilter_Insert() 함수가 실행되는데, 이 함수는 이미 있는 원소도 중복으로 삽입해요. CuckooFilter_InsertUnique() 함수를 써야만 집합의 동작을 보장할 수 있죠.
그래서, Redis에서 CF가 집합처럼 동작하길 기대한다면 CF.ADD 대신 CF.ADDNX 를 사용해야 해요.
127.0.0.1:6379> CF.RESERVE myfilter 1000
OK
127.0.0.1:6379> CF.ADDNX myfilter "1"
(integer) 1
127.0.0.1:6379> CF.ADD myfilter "1"
(integer) 1
127.0.0.1:6379> CF.DEL myfilter "1"
(integer) 1
127.0.0.1:6379> CF.EXISTS myfilter "1"
(integer) 1 //개별 요소로 간주해서 남아있음
DEL myfilter //cleanup
-------------------------------------------------
127.0.0.1:6379> CF.RESERVE myfilter 1000
OK
127.0.0.1:6379> CF.ADDNX myfilter "1"
(integer) 1
127.0.0.1:6379> CF.ADDNX myfilter "1"
(integer) 0
127.0.0.1:6379> CF.DEL myfilter "1"
(integer) 1
127.0.0.1:6379> CF.EXISTS myfilter "1"
(integer) 0 // 제대로 삭제됨
TMI
Scalable
BF와 마찬가지로 CF 자체는 확장할 수 없지만, Redis에서는 여러 CF를 체인으로 연결하기 때문에 확장이 가능해요.
false positive, false deletion
BF에서는 “없는데 있다”는 거짓 긍정(false positive)만 발생하고, “있는데 없다”는 거짓 부정(false negative)는 절대 발생하지 않아요.
CF도 동일하지만, 존재하지 않는 키를 삭제하지 않는 한 이라는 조건이 붙어요. 이건 좀 재미있어보여서 다음 글에서 다뤄볼게요.
Final
CF는 BF처럼 집합에 원소가 존재하는지를 효율적으로 판단하면서, 삭제까지 지원해요. 다만 확률적 자료구조여서 false positive 가능성을 생각해야 하죠. BF와 유사한만큼, 존재 여부를 빠르게 확인하는 전처리 필터로 사용할 수 있어요.
많은 블로그 글 등에선 CF는 false negative 가능성이 없다고 하지만, 원소를 잘못 삭제할 경우엔 문제가 될 수 있는데요, 다음 글에서는 이 현상을 간단히 확인해볼게요.
3-point
- CF는 메모리 효율적으로 집합에 원소가 있는지 확인하는 확률적 자료구조이고, 삭제도 가능하다.
- 마치 뻐꾸기처럼 자리가 없으면 쫓아내면서 동작한다.
- 거짓 긍정은 발생할 수 있고, 거짓 부정은 발생하지 않지만, 잘못 삭제하면….



